
せっかくなので、まとめました。 High Sierra環境下での報告です。参考にされる方は自己責任で。
まとめる適切な場所がなくて、院生時代に作った大昔のWordPressで作成したのでとても見にくい。今度ここもきれいに直さなくては。。
Office2016を導入して困った点としてはフォントの問題。デフォルトで游ゴシックLightになっていること。まあこのフォント自体は読みやすいし、結構気に入っているんだけど、論文とかそういうので指定されているMS明朝とかMSゴシックに変更するために結構遠くまで探しにいかないといけない。カーソル使ってゴリゴリと。あーもうめんどくさい。
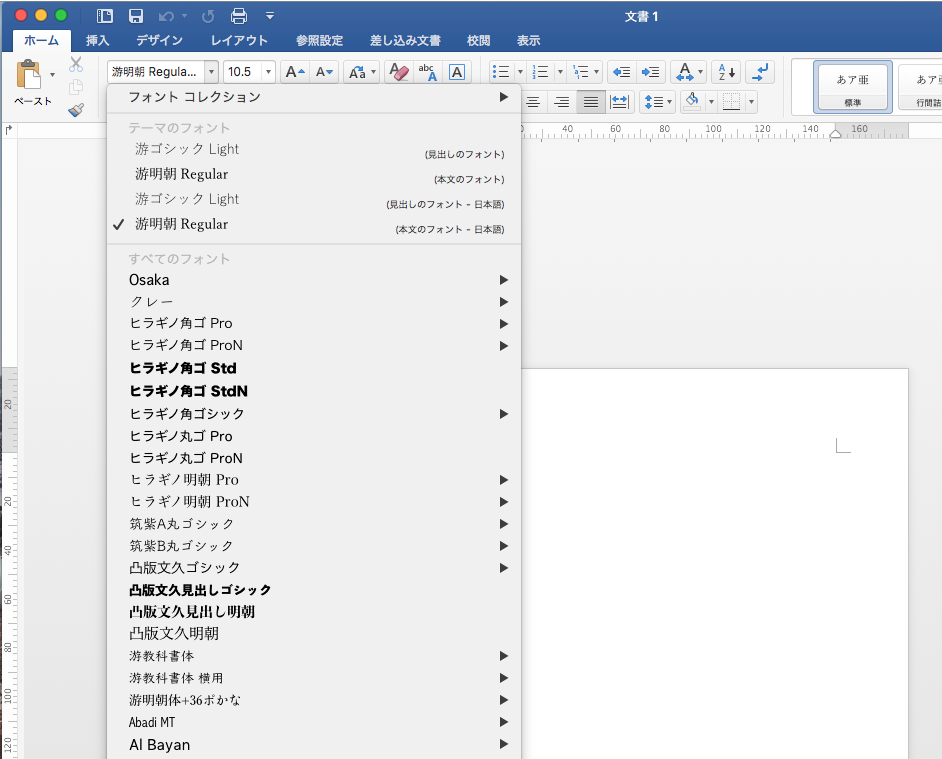
MSシリーズとか、Times new romanとか結構下のほうまでいかんといかん。。。
ということで、Twitterでつぶやいてみたら、神降臨。
Font Bookアプリケーションで「*よく使う」とかってフォントコレクション作って、フォントコレクションから選ぶようにする、ではダメ?
あと、同じくFont Bookで、ぜってー使わないフォントは使用停止するとか。— @RBootcamp (@RBootcamper001) 2019年4月13日
ということで試してみた。
まずは最初のにトライ。Font Book.appを立ち上げて、すべてのフォントから、使わないすべてのフォントをガツンと利用停止。これによって基本的に使わないフォントは表示されなくなる。
こんな感じになる。これならばまあいつでももう一度有効にすればいいだけなので、削除しちゃうのはなんだか怖いって人にも安心。
とはいってももしかしたら、どんなフォントでもいつか使うかもしれんし (まあつかわんじゃろうけど)、ちょっと全部停止するのは抵抗あるなあと思う人は、もう一つ教えてもらった、コレクション機能を使うという方法もある。
まずコレクション機能は、Wordのフォントのところに出てくるコレのこと。
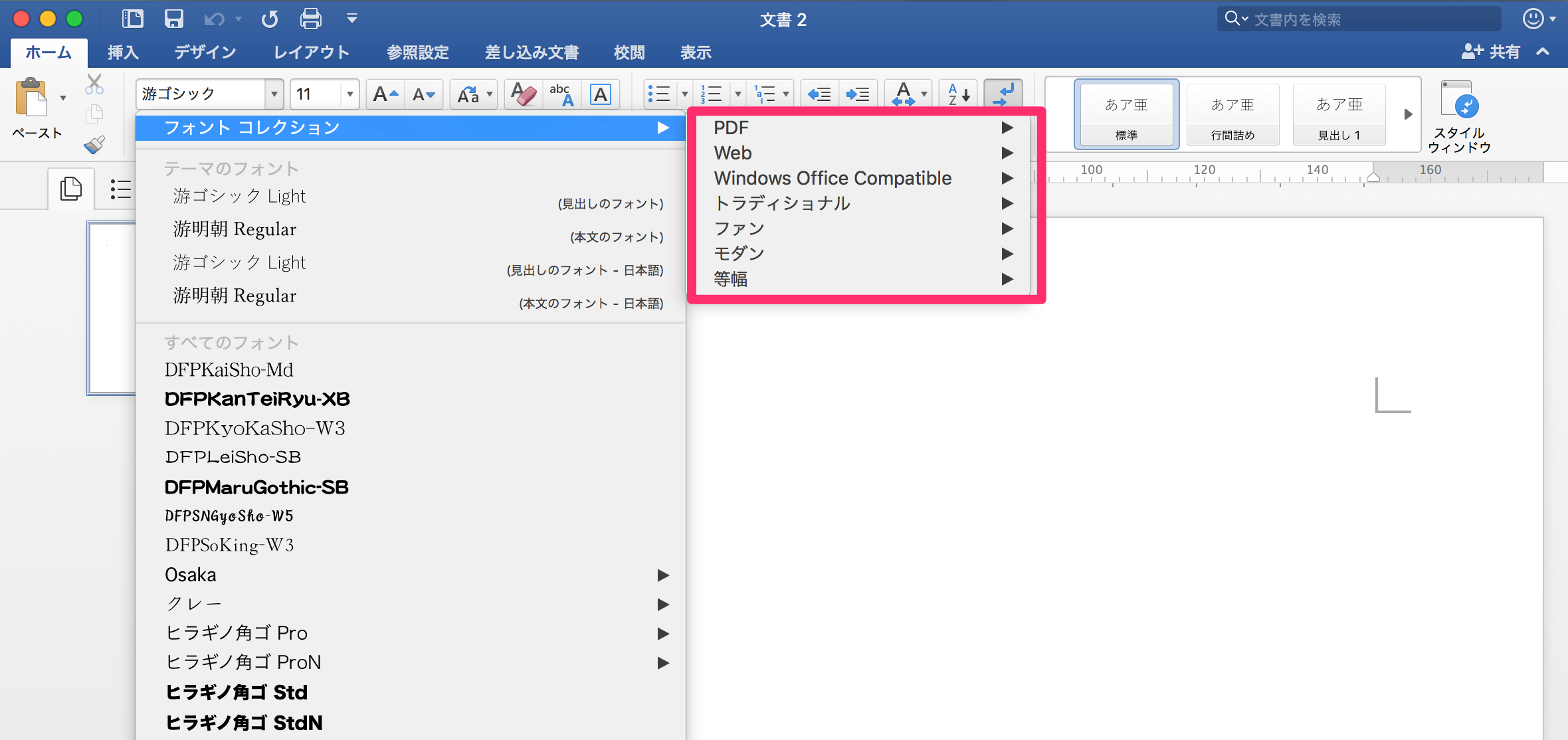
デフォルト状態で結構いろいろ設定されている。いろいろな用途に応じたフォントが収納されているボックスのようなものと考えればいいと思う。僕の場合、今まで使ったことはなかった。FontBook.appで見るとこんな感じでコレクションされている。


とりあえず、面倒くさいので全部のコレクションを消去 。ここで注意しないといけないのは、使用停止ではなくて消去を選ぶこと。これはコレクションを消すという意味でフォントはそのものはすべてのフォントの中に残っているので安心。Macのアプリってこんな感じの作りが多い
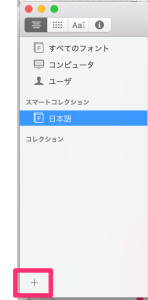
めっちゃすっきりしたので、+を押して新しいコレクションを作成する。

僕の場合は、よく使うフォントと名付けた。続いて、作成したよく使うフォントのフォルダの中に、すべてのフォントから必要なフォントをドラックしてしまえばいい。僕の場合は、times new romanとメイリオとヒラギノシリーズ、MS明朝かな?
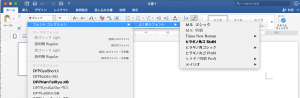
Wordの場面。コレでだいぶ簡単になった。
ちなみに、デフォルトのフォントを変えるためには、W右クリックで出てくるフォントを選択して、こんな感じにすれば いい。

僕の場合は、最初はMS明朝とTimes new romanでしばらく過ごして見ようと思う。
(注) Mac環境の一部では、すべてのフォントの中にMSゴチとMS明朝が見つからなかいことがありるみたいです。なぜか、Officeでは使えるのにMacのフォントそのものにはインストールされていないという現象が起こる。おそらく、古いOfficeをインストールしていない状況で、最初から2016をインストールした人はこうなってしまうみたい。その場合、Window10のフォントをコピーしてきて、Macにインストールという作業によってなんとかなるはずです。そこら辺はこちらのサイトが参考になりました。ありがとうございます!
Windows の標準フォントを Mac で使う方法 http://tokyo.secret.jp/macs/font-mac-windows.html

































